")





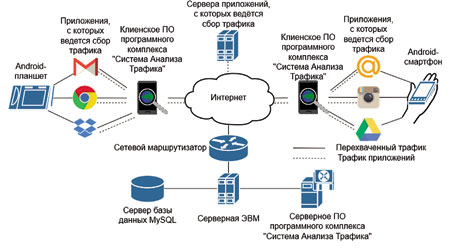
To assess the effectiveness of classification algorithms in the training and testing modes, a database of mobile applications for traffic, WEB (http, https), mail (SMTP, IMAP), Skype (TCP, UDP), etc. was developed using the developed software and hardware complex.
Of the traffic streams received, 66% of the source data was used for training, the rest for testing the classification algorithms for selected applications using machine-learning methods. The following algorithms were considered as classification algorithms: Random Forest, С4.5, SVM, Adaboost, and Naive Bayes.
To justify the choice of the number of classification attributes, the wrapping and filtering methods were used. It is shown that some attributes used to classify traffic do not carry meaningful information, and their use does not significantly affect the classification efficiency.
Algorithms for the selection of classification attributes are considered: PCA, InfoGain, CFS, and Wrapper. It is shown that the use of the attribute selection-wrapping algorithm is a resource-intensive computational operation, which, with a large number of attributes, takes a long time.
It is shown that among the considered classification algorithms, preference should be given to the C4.5 algorithm.
A comparative analysis of the selection algorithms for the informative attributes of mobile applications has shown that the most efficient and easily implemented is the InfoGain algorithm.
A specific feature of the classification of mobile applications is the high information content of only a few attributes. When choosing a method for selecting attributes, the most preferred algorithm is to select the most informative attribute first and add the following less informative attributes to it.
For a quantitative assessment of the selection of the number of attributes, a selection algorithm based on their information content is proposed.