")





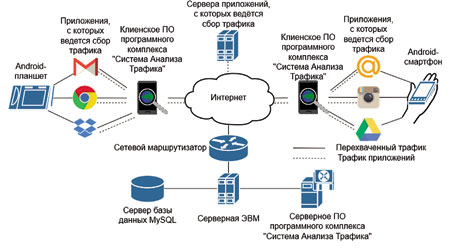
Для оценки эффективности алгоритмов классификации в режимах обучения и тестирования с помощью разработанного программно-аппаратного комплекса была сформирована база данных мобильных приложений трафика, WEB (http, https), mail (SMTP, IMAP), Skype (TCP, UDP) и др.
Из полученных потоков трафика 66% исходных данных использовались для обучения, остальные для тестирования алгоритмов классификации выбранных приложений методами машинного обучения. В качестве алгоритмов классификации методами машинного обучения рассматривались: Random Forest, С4.5, SVM, Adaboost, Naive Bayes.
Для обоснования выбора количества атрибутов классификации использовались оберточный и фильтрующий методы. Показано, что некоторые атрибуты, используемые для классификации трафика, не несут значимой информации, и их использование незначительно влияет на эффективность классификации.
Рассмотрены алгоритмы выбора атрибутов классификации: PCA, InfoGain, CFS, Wrapper. Показано, что использование оберточного алгоритма выбора атрибутов является ресурсоемкой вычислительной операцией, которая при большом количестве атрибутов требует длительного времени.
Показано, что среди рассмотренных алгоритмов классификации предпочтение следует отдать алгоритму С4.5.
Сравнительный анализ алгоритмов отбора информативных атрибутов мобильных приложений показал, что наиболее эффективным и легко реализуемым является алгоритм InfoGain.
Специфической особенностью классификации мобильных приложений является высокая информативность всего нескольких атрибутов. При выборе способа отбора атрибутов наиболее предпочтителен алгоритм, при котором сначала отбирается наиболее информативный атрибут, а к нему добавляются следующие менее информативные.
Для количественной оценки отбора количества атрибутов предложен алгоритм отбора на основе их информативности.