")





Рассмотрена актуальная задача контроля доступа к Интернет-ресурсам имеющая важное прикладное значение: блокирование доступа к нелегальной, экстремистской, антисоциальной информации, предотвращение утечки конфиденциальной информации через Интернет и др.
Для решения подобных задач широкое распространение используются методы машинного обучения. Традиционные методы классификации сетевого трафика, основанные как на номерах портов, так и на информационной нагрузке, полагаются на прямое изучение сетевых пакетов. При наличии полного и помеченного тренировочного набора данных, целесообразно строить классификатор, используя технологии машинного обучения (Machine Learning) и интеллектуального анализа данных (Data Mining), оказавшиеся наиболее эффективными. Создание «идеального» классификатора невозможно пока не будут решены проблемы, присущие данной области. Прежде всего это отсутствие общего, репрезентативного набора исходных данных, который мог бы стать стандартным для исследований в данной области. Большинство известных работ посвященных проблеме классификации трафика опускают фундаментальное требование определения неизвестного типа трафика.
Целью работы является исследование эффективности алгоритмов классификации приложений сетевого трафика в условиях наличия фонового трафика.
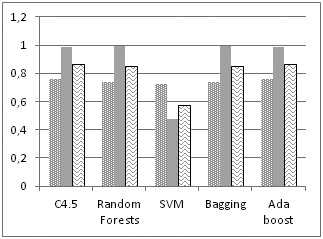
Новизной представленного решения является анализ следующих групп приложений: Web –протоколы просмотра web-сайтов – http, https; ftp –протокол для передачи файлов ftp; mail –протоколы для передачи электронной почты – SMTP, POP3, IMAP; p2p –протоколы приложений, использующие пиринговые сети для передачи файлов путем использования алгоритмов машинного обучения: С4.5; Random Forests; Support Vector Machine; Bagging и Adaptive Boost в условиях наличия неклассифицируемогоо (фонового) трафика. Показано, что качество классификации в условиях наличия фонового трафика снижается для всех рассматриваемых алгоритмах классификации. Однако поскольку алгоритмы C4.5, Random Forests, Bagging и AdaBoost построены на использовании деревьев принятия решений – одного в случае (С4.5) или множества, их характеристики остаются достаточно высокими и отличаются незначительно.