")





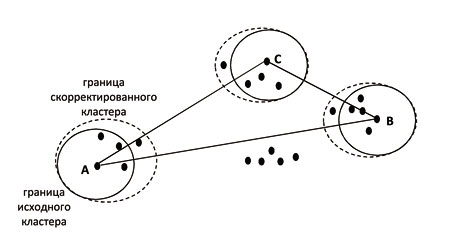
Наиболее значимой составляющей автоматизированной обработки информации является автоматический анализ данных. Наряду с классическими процедурами статистического анализа – факторного, дисперсионного, дискриминантного и др. – он также включает ряд дополнительных процедур, не связанных напрямую со статистическим анализом.
К ним, в частности относятся процедуры генетической оптимизации, классификации без учителя путем кластеризации исходной выборки данных, методы адаптации перцептронного классификатора по обучающей выборке, а также процедура нечеткого управления. В настоящее время предпринимаются значительные усилия по объединению подобных процедур в рамках единой интеллектуальной технологии. В рамках этих усилий здесь рассматриваются некоторые модификации указанных процедур путем их существенного упрощения – как идеологически, так и в части реализации. Проведенное рассмотрение показало, что они имеют сравнительно простую основу. Так, генетическая оптимизация была сведена к двухшаговой версии случайного поиска экстремума, шагами в которой является предварительное смешивание результатов первичного поиска, аналогичное скрещиванию, и вторичный случайный поиск в выделенной области, соответствующий мутации. Метод потенциальных функций позволил сравнительно просто реализовать автоматическую кластеризацию входной выборки без ограничений на ее характер. В предложенном алгоритме обучения перцептронного классификатора обработка в ассоциативном нейроне была реализована в виде усреднение сигналов от подключенных рецепторов с вычитанием постоянной величины. Дополнительное использование условия нормировки адаптивных коэффициентов делает ее малосущественной при использовании выбора максимума в качестве решающего правила. Методически несложно реализована процедура обучения алгоритма нечеткого управления, базирующаяся на выравнивании частот реализации управляющих воздействий при использовании эквидистантной выборки входных состояний.